Storage Systems I
Info 253: Web Architecture
Kay Ashaolu
Why data storage?
- When we make a web request, where do we get the data from?
- When we create data, where do we put it?
- Where do "resources" live?
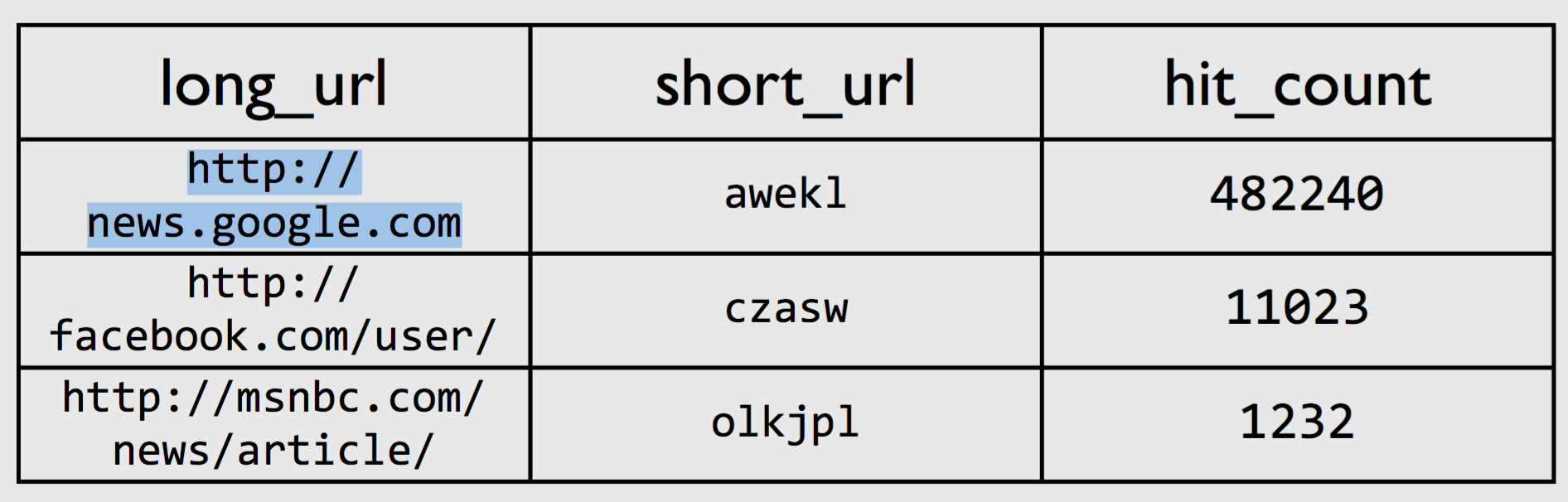
Example: bit.ly
- Lots of data to store
- Shortcut to url mapping
- Statistics about links
- Information about users
Example: bit.ly
long url http://news.google.com
short url http://bit.ly/awekl
hit count 482240
long url http://facebook.com/user/profile
short url http://bit.ly/czasw
hit count 11023
long url http://msnbc.com/news/article/
short url http://bit.ly/olkjpl
hit count 1232
Data Storage Design
- What is the storage format?
- How do we lay out data?
- How do we access data?
Why use a file?
- http://news.google.com, http://bit.ly/awekl, 482240
- http://facebook.com/user/profile, http://bit.ly/czasw, 11023
- http://msnbc.com/news/article, http://bit.ly/olkjpl, 1232
- What are the pros and cons?
Problems with Files
- What if we want to add another field?
- What if we want to query different parts of data? How efficient is this?
- What if we have concurrent accesses?
- What data structures should we use?
Data Independence
- Databases: apps shouldn’t have to worry about these problems!
- Underlying storage format independent of application-level logic
Relational Data Stores
- RDBMS: Relational Database Management System
- Invented in the 1970s
- e.g., Oracle, MySQL, Postgres, IBM DB2, Microsoft SQL Server
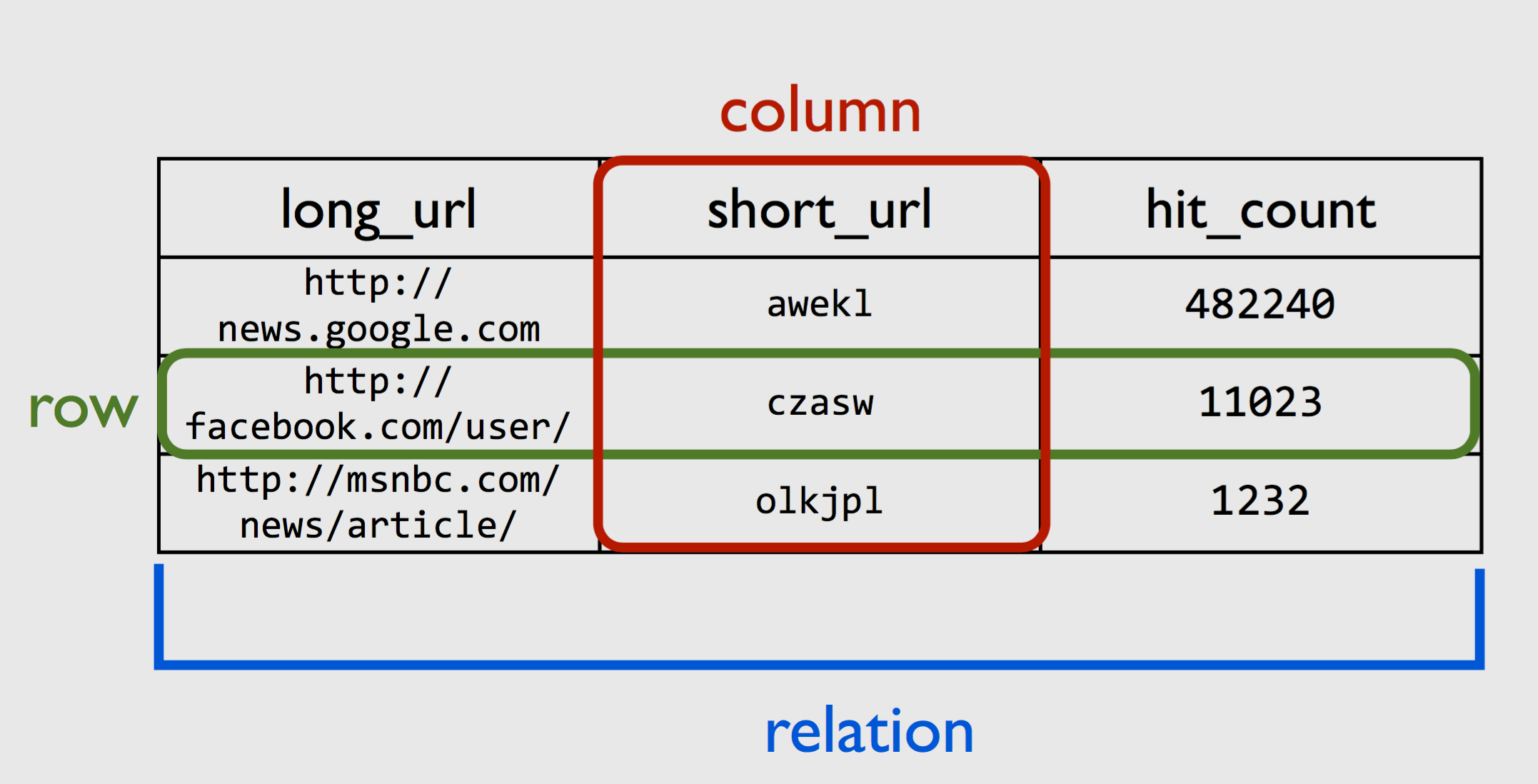
Relational Model
- Reason about sets of facts, or "tables"
- Each fact is a "row"
- Attributes are "columns" of row
For Example
For Example
SQL Query Language
- High-level query language over tables
- Declarative: say "what" you want computed, not "how"
- Why is this good?
Select Example
SELECT * FROM links;
| long_url |
short_url |
hit_count |
created |
| http://www.google.com |
qwelmw |
2 |
2016-4-5 |
| http://www.facebook.com |
adfer |
45 |
2016-8-5 |
2 rows in set (0.00 sec)
Select Example
SELECT * FROM links WHERE hit_count < 20;
| long_url |
short_url |
hit_count |
created |
| http://www.google.com |
qwelmw |
2 |
2016-4-5 |
1 row in set (0.00 sec)
INSERT Example
INSERT INTO links VALUES ("http://www.twitter.com", "eovle", 0, CURDATE());
Query OK, 1 row affected (0.00 sec)
SELECT * FROM links;
| long_url |
short_url |
hit_count |
created |
| http://www.google.com |
qwelmw |
2 |
2016-4-5 |
| http://www.facebook.com |
adfer |
45 |
2016-8-5 |
| http://www.twitter.com |
eovle |
0 |
2016-10-28 |
3 rows in set (0.00 sec)
UPDATE example
UPDATE links SET hit_count = '0' WHERE created < '2016-10-22';
Query OK, 2 rows affected (0.00 sec)
Rows matched: 2 Changed: 2 Warnings: 0
SELECT * FROM links;
| long_url |
short_url |
hit_count |
created |
| http://www.google.com |
qwelmw |
0 |
2016-4-5 |
| http://www.facebook.com |
adfer |
0 |
2016-8-5 |
| http://www.twitter.com |
eovle |
9 |
2016-10-28 |
3 rows in set (0.00 sec)
Useful Properties
- Atomicity: all updates happen or none do
- Consistency: easy to reason about database
- Isolation: operations are separated from each other
- Durability: updates won’t disappear
RDBMS Pros and Cons
Pros
- High-level query language
- High Data integrity
- Data independence
Cons
- Have to define schema at start
- Scaling can be complicated
- Can become slow